it's easy to see that this implies
which is the same as
This tells us that
If you have a relation of the form
![]() such that
such that![]()
it's easy to see that this implies![]()
which is the same as![]()
This tells us that![]() and
and![]() are two factors of n.
are two factors of n.
![]()
We can see that the following relation is satisfied
![]()
so the right side is already a square for any x.
Now consider a set of prime numbers
![]() called the factor base and assume that we have found two x values such that f(x) factors completely over the factor base. For example:
called the factor base and assume that we have found two x values such that f(x) factors completely over the factor base. For example:
![]()
![]()
Neither of these values are square, but by multiplying them we get
![]()
which clearly is a square.
Now we have two relations:
![]() and
and![]()
Multiplying them we get
![]()
which is a relation of the form we are looking for. This can of course be generalised to several values of x instead of just 2. We can now compute the gcd as described above and we have a factorisation of n. Computing the gcd can be done efficiently using the extended Euclidean algorithm.
Let's now take a look at how this can be done in practice.
![]()
Inserting the value for f we see that
![]()
This means that n is a quadratic residue modulo p and hence our factor base should only consist of primes such that this is the case. Still, we should choose the primes as small as possible.
First we can show that
![]()
In order to obtain an initial solution (a value of x such that p|f(x) ) consider the following
![]()
It is clear that this equation has at least two solutions and by what we have shown above, any solution will differ from one of these solutions by a multiple of p. These two solutions depend only on p and n so when we generate the factor base, we also compute and store them for each prime in the factor base.
An algorithm called the Shanks-Tonelli Algorithm can be used to compute these modular square roots efficiently.
Now we know enough to describe a somewhat efficient way of doing the sieving step.
First pick an interval close to 0 and compute log(f(x)) for each x in the interval.
Now loop over all primes in the factor base and for each x in the interval where p|f(x) we subtract log(p) from log(f(x))
We can do this efficiently because we already know all the values of x that satisfy this.
A value of f(x) that factors completely over the factor base should theoretically have it's 'log(f(x))' reduced to zero by this procedure (remember that log(f(x)) - log(p) = log(f(x)/p). However this is not always the case because
The matrix is in GF(2) and has factor_base_size columns and factor_base_size + 10 rows (will be explained in the next section). Each row corresponds to one value of f(x) and the column i contains a 1 if the i'th element of the factor base was a factor of f(x) occurring an odd number of times and a 0 if it occurred an even number of times.
The sieving step ends when we have filled the matrix. If that does not happen in the chosen interval we will just pick another and repeat the sieving step. However, if the factor base was too large or too small we might have to wait a very long time for the matrix to be filled because the values of f(x) become larger and hence more unlikely to factor over the factor base.
If we call the i'th row of A![]() and
and![]() is either 0 or 1, then what I have just written above is actually that we want to choose values of
is either 0 or 1, then what I have just written above is actually that we want to choose values of![]() such that
such that![]()
This means that we have to solve
![]()
where
![]()
Once we have this solution the![]() 's that are 1 will tell us which f(x) values to multiply to get a relation of the form we are looking for.
's that are 1 will tell us which f(x) values to multiply to get a relation of the form we are looking for.
This can be solved by augmenting A with the identity matrix I and performing Gaussian elimination on the augmented matrix. After the Gaussian elimination we can read the e vector as a row in I next to a 0 row in A (this is probably not obvious, but don't worry about that).
There are more efficient ways of solving this since we can take advantage of the fact that the matrix is a sparse matrix in GF(2) with most non-zero entries to the left.
Once we have the solutions we multiply them and use the extended Euclidean algorithm to compute the gcd as described in the beginning, obtaining a factorisation of n.
Because our original matrix had 10 more rows than columns we have at least 10 different solutions which is good because for each solution there is a fifty-fifty chance that it will yield the trivial factorisation of n.
There are several variations of this algorithm. Here I will just present one of them.
Finally we choose C such that![]()
This is possible due to our choice of B. Now look what happens when we multiply f(x) by A:
![]()
If we look closely at the relation above we see that we can use this new f(x) just as we did before. The crucial point here is that even if we multiply values of f(x) obtained with different values of A, B and C we still get a relation of the form we are looking for. So when one polynomial gets too large we discard it and choose a new one. This is why this is called the multiple polynomial version.
Then our maximum must be in -M or M and it will roughly be of size![]() . We want this to be as close to
. We want this to be as close to![]() as possible so we choose
as possible so we choose![]()
To help us select a suitable A choose a prime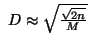 such that n is a square modulo D and
such that n is a square modulo D and![]() .
.
Set![]() . A is now close to the value we wanted and we also know that n is a square modulo q for every prime q that divides A.
. A is now close to the value we wanted and we also know that n is a square modulo q for every prime q that divides A.
Now we need to find B. Consider the following values and keep in mind that![]()
![]()
![]()
This gives us
![]()
Now define
![]()
The inverse of![]() always exists since we are in
always exists since we are in![]() where D is a prime and can be computed efficiently using the extended Euclidean algorithm.
where D is a prime and can be computed efficiently using the extended Euclidean algorithm.
Now we can choose![]() which can be easily checked to satisfy
which can be easily checked to satisfy![]()
Finally C can be chosen by solving![]() which will always have a solution due to the choice of B.
which will always have a solution due to the choice of B.
When we need a new polynomial we just choose the next D that satisfies the requirements and generate new values of A, B and C.
There are other things to consider. What about the factor base for example? We must of course keep the same factor base for all polynomials so is the requirement that all primes in the factor base should be chosen such that n is a quadratic residue modulo each of them still valid? Remember that the reason for choosing the factor base this way, was that we only wanted primes where for at least one x it was the case that p | f(x). Recall that:
![]()
Let p be a prime in the factor base:
![]()
So if we choose A such that there does not exist primes in the factor base that divides A this is equivalent to require that for each prime p in the factor base, n is a quadratic residue modulo p. Hence we only have a problem if a prime in the factor base is equal to D. Note that even if this happens the only harm done is that we will have one element in the factor base that never divides f(x).
Bottom line is that we choose the factor base just as before.
Just as before we need to solve f(x) = 0 (mod p) for each prime in the factor base, but this time we need to do it each time we generate a new polynomial. This is easy to do using the standard formula for solving a polynomial of 2nd degree.
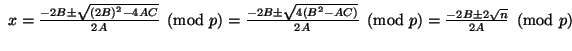
![]() can be computed using the Shanks-Tonelli algorithm and the inverse of 2A can always be found since we are in
can be computed using the Shanks-Tonelli algorithm and the inverse of 2A can always be found since we are in![]() where p is a prime. Of course
where p is a prime. Of course![]() can be precomputed for each prime in the factor base.
can be precomputed for each prime in the factor base.
The rest of the algorithm works exactly the same way as in the single polynomial case, except for the fact that we don't keep sieving until we have enough relations, but instead choose a new polynomial and restart the sieving once f(x) gets too large.
A simple optimisation is the Small Prime Variation. The idea is that small primes doesn't contribute much to the sieving so we might as well stop wasting our time on them. Of course we have to adjust the sieving threshold a little.
Another related optimisation is the Large Prime Variation. Here the idea is that even though a number doesn't fully factor over the factor base we can still use that number. If we can factor the number over the factor base with a remainder that is one large prime, we store the number and the large prime. If we later find a number that factors completely except for the same large prime we can now use these two numbers since the result will still be a square if it includes these two numbers. The name can be a bit misleading since the "large prime" doesn't have to be a prime at all. Still we need some criteria for the numbers to keep or else we will quickly run out of memory, requiring that these extra numbers are primes are one way to increase the chance that we will find two f(x) values with the same large prime as a factor. Of course this method can be extended to two large primes instead of only one at the cost of more memory usage.
A very useful optimisation regarding a parallel implementation of the multiple polynomial version is to choose A different from what I described above. If we choose A to be a product of k primes not in the factor base we can find![]() values of B that can be used for each A, that is they satisfy
values of B that can be used for each A, that is they satisfy![]() . This allows the server to choose a value of A and send it to the client. The client can now compute several polynomials on it's own without having to communicate with the server. This would be very useful for a distributed factoring algorithm over the internet.
. This allows the server to choose a value of A and send it to the client. The client can now compute several polynomials on it's own without having to communicate with the server. This would be very useful for a distributed factoring algorithm over the internet.
I have found "optimal" values in the literature for the relation between the size of the factor base and the sieving interval, but the literature is also full of empirical results that do not match the theoretic optimal values. Basically what you do if you want to factor a large number is that you do a lot of analysis of that number and generate special polynomials. Also for some values of n it's better to factor a multiple of n instead since that would suit the selected polynomial better. Of course if you really want to factor large numbers today you would probably not use the quadratic sieve, but the number field sieve instead which is faster for really large numbers (more that 130 digits or so). If you want to factor small primes (less than 13 digits or so) there are methods that are a lot faster than the quadratic sieve.
I'll end this section with running times for the quadratic sieve and the number field sieve given the theoretical optimal values. These numbers are taken from "Stinson: Cryptography - Theory and Practice".
| Quadratic sieve: |
|
| Number field sieve: |
|